

Bilgi işlem ve bilgi biliminde bilgi alma (IR), bir bilgi ihtiyacıyla ilgili bilgi sistemi kaynaklarının bu kaynakların bir koleksiyonundan elde edilmesi sürecidir. Aramalar, tam metin veya diğer içerik tabanlı indekslemeye dayalı olabilir. Bilgi erişimi, bir belgede bilgi arama, belgelerin kendilerini arama ve ayrıca verileri tanımlayan meta verileri ve metin, görüntü veya ses veritabanlarını arama bilimidir[1].
Otomatik bilgi erişim sistemleri, bilgi yüklemesi olarak adlandırılan şeyi azaltmak için kullanılır. IR sistemi, kitaplara, dergilere ve diğer belgelere erişim sağlayan bir yazılım sistemidir; bu belgeleri saklar ve yönetir. Web arama motorları en görünür IR uygulamalarıdır.
Genel bakış
Bilgi alma süreci, bir kullanıcı veya araştırmacı sisteme bir sorgu girdiğinde başlar. Sorgular, örneğin web arama motorlarındaki arama dizeleri gibi bilgi gereksinimlerinin resmi ifadeleridir. Bilgi almada, bir sorgu, koleksiyondaki tek bir nesneyi benzersiz bir şekilde tanımlamaz. Bunun yerine, birkaç nesne, belki de farklı alaka dereceleriyle sorguyla eşleşebilir.
Nesne, bir içerik koleksiyonundaki veya veritabanındaki bilgilerle temsil edilen bir varlıktır. Kullanıcı sorguları veritabanı bilgileriyle eşleştirilir. Bununla birlikte, bir veritabanının klasik SQL sorgularının aksine, bilgi almada döndürülen sonuçlar sorguyla eşleşebilir veya eşleşmeyebilir, bu nedenle sonuçlar genellikle sıralanır. Sonuçların bu sıralaması, veritabanı aramasıyla karşılaştırıldığında bilgi alma aramasının önemli bir farkıdır.[2]
Uygulamaya bağlı olarak veri nesneleri, örneğin metin belgeleri, resimler,[3] ses,[4] zihin haritaları[5] veya videolar olabilir. Genellikle belgelerin kendileri doğrudan IR sisteminde tutulmaz veya depolanmaz, bunun yerine sistemde belge vekilleri veya meta verilerle temsil edilir.
Çoğu IR sistemi, veritabanındaki her nesnenin sorguyla ne kadar iyi eşleştiğine dair sayısal bir puan hesaplar ve nesneleri bu değere göre sıralar. En üst sıradaki nesneler daha sonra kullanıcıya gösterilir. Kullanıcı sorguyu geliştirmek isterse süreç yinelenebilir.[6]
Tarihi
İlgili bilgi parçalarını aramak için bilgisayarları kullanma fikri, 1945’te Vannevar Bush tarafından Düşündüğümüz Gibi makalesinde popüler hale getirildi.[7] Görünüşe göre Bush, 1920’lerde ve 30’larda Emanuel Goldberg tarafından dosyalanan ve filmde saklanan belgeleri arayan bir ‘istatistik makinesi’ için alınan patentlerden ilham almış görünüyor.[8] Bilgi arayan bir bilgisayarın ilk tanımı, 1948’de Holmstrom tarafından,[9] Univac bilgisayarının erken bir sözünü detaylandırarak açıklandı. Otomatikleştirilmiş bilgi erişim sistemleri 1950’lerde tanıtıldı: hatta bunlardan biri 1957 romantik komedi Desk Set’te yer aldı.1960’larda, ilk büyük bilgi erişim araştırma grubu Cornell’de Gerard Salton tarafından kuruldu. 1970’lere gelindiğinde, birkaç farklı alma tekniğinin, Cranfield koleksiyonu (birkaç bin belge) gibi küçük metin külliyatlarında iyi performans gösterdiği gösterildi.[7] Lockheed Dialog sistemi gibi büyük ölçekli geri alma sistemleri 1970’lerin başında kullanılmaya başlandı.
1992’de ABD Savunma Bakanlığı, Ulusal Standartlar ve Teknoloji Enstitüsü (NIST) ile birlikte TIPSTER metin programının bir parçası olarak Metin Erişim Konferansı’na (TREC) sponsor oldu. Bunun amacı, çok geniş bir metin koleksiyonu üzerinde metin erişim metodolojilerinin değerlendirilmesi için gerekli olan altyapıyı sağlayarak bilgi erişim topluluğuna bakmaktı. Bu, devasa dercelere ölçeklenen yöntemler üzerine araştırmayı katalize etti. Web arama motorlarının tanıtımı, çok büyük ölçekli erişim sistemlerine olan ihtiyacı daha da artırdı.
Uygulamalar
Bilgi alma tekniklerinin kullanıldığı alanlar şunları içerir (girişler her kategoride alfabetik sıradadır):
Genel uygulamalar
Dijital kütüphaneler
Bilgi filtreleme
Önerilen sistemler
Medya arama
blog araması
görüntü alma
3D alma
Müzik alma
Haber arama
konuşma alma
Video alma
Arama motorları
site arama
Masaüstü araması
kurumsal arama
Birleşik arama
mobil arama
Sosyal aramalar
internette arama
Etki alanına özel uygulamalar
Uzman arama bulgusu
Genomik bilgi alma
Coğrafi bilgi alma
Kimyasal yapılar için bilgi alma
Yazılım mühendisliğinde bilgi alma
Yasal bilgi alma
dikey arama
Diğer alma yöntemleri
Bilgi alma tekniklerinin kullanıldığı Yöntemler/Teknikler şunları içerir:
Düşman bilgi alma
Otomatik özetleme
Çoklu belge özetleme
Bileşik terim işleme
Diller arası erişim
Belge sınıflandırması
Spam filtreleme
soru cevaplama
Model Tipleri
İlgili belgeleri IR stratejileriyle etkili bir şekilde almak için, belgeler tipik olarak uygun bir sunuma dönüştürülür. Her alma stratejisi, belge temsili amaçları için belirli bir model içerir. Aşağıdaki resim, bazı yaygın modellerin ilişkisini göstermektedir. Resimde modeller iki boyuta göre kategorize edilmiştir: matematiksel temel ve modelin özellikleri.
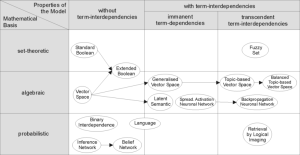
Birinci boyut: matematiksel temel
Küme-teorik modeller, belgeleri sözcük veya deyim kümeleri olarak temsil eder. Benzerlikler genellikle bu kümeler üzerindeki küme-teorik işlemlerden elde edilir. Yaygın modeller şunlardır:
- Standart Boole modeli
- Genişletilmiş Boole modeli
- Bulanık alma
Cebirsel modeller belgeleri ve sorguları genellikle vektörler, matrisler veya demetler olarak temsil eder. Sorgu vektörü ile belge vektörünün benzerliği, bir skaler değer olarak temsil edilir.
- Vektör uzayı modeli
- Genelleştirilmiş vektör uzayı modeli
- (Geliştirilmiş) Konu Tabanlı Vektör Uzayı Modeli
- Genişletilmiş Boole modeli
- Gizli semantik indeksleme a.k.a. gizli semantik analiz
Olasılık modelleri, belge alma sürecini olasılıksal bir çıkarım olarak ele alır. Benzerlikler, bir belgenin belirli bir sorgu için alakalı olma olasılıkları olarak hesaplanır. Bayes teoremi gibi olasılıksal teoremler bu modellerde sıklıkla kullanılır.
- İkili bağımsızlık modeli
- Okapi (BM25) uygunluk fonksiyonunun dayandığı olasılıksal alaka modeli
- Belirsiz çıkarım
- Dil modelleri
- Rastgelelikten sapma modeli
- Gizli Dirichlet tahsisi
Özellik tabanlı alma modelleri, belgeleri özellik işlevlerinin (veya yalnızca özelliklerin) değerlerinin vektörleri olarak görür ve genellikle yöntemleri sıralamayı öğrenerek bu özellikleri tek bir alaka düzeyi puanında birleştirmenin en iyi yolunu arar. Özellik işlevleri, belge ve sorgunun isteğe bağlı işlevleridir ve bu nedenle, hemen hemen tüm diğer alma modellerini başka bir özellik olarak kolayca birleştirebilir.
İkinci boyut: modelin özellikleri
Terim bağımlılığı olmayan modeller, farklı terimleri/kelimeleri bağımsız olarak ele alır. Bu gerçek genellikle vektör uzay modellerinde terim vektörlerinin ortogonallik varsayımıyla veya olasılık modellerinde terim değişkenleri için bir bağımsızlık varsayımıyla temsil edilir.
İçkin terim bağımlılıkları olan modeller, terimler arasındaki karşılıklı bağımlılıkların bir temsiline izin verir. Ancak, iki terim arasındaki karşılıklı bağımlılığın derecesi modelin kendisi tarafından tanımlanır. Genellikle doğrudan veya dolaylı olarak (örneğin, boyutsal indirgeme yoluyla) bu terimlerin tüm belgelerde bir arada bulunmasından türetilir.
Aşkın terim bağımlılığına sahip modeller, terimler arasındaki karşılıklı bağımlılığın bir temsiline izin verir, ancak iki terim arasındaki karşılıklı bağımlılığın nasıl tanımlandığını iddia etmezler. İki terim arasındaki karşılıklı bağımlılığın derecesi için bir dış kaynağa güvenirler. (Örneğin, bir insan veya gelişmiş algoritmalar.)
Performans ve doğruluk ölçütleri
Bir bilgi erişim sisteminin değerlendirilmesi, bir sistemin kullanıcılarının bilgi ihtiyaçlarını ne kadar iyi karşıladığını değerlendirme sürecidir. Genel olarak ölçüm, aranacak belgeler koleksiyonunu ve bir arama sorgusunu dikkate alır. Boolean alma[açıklama gerekli] veya üst-k alma için tasarlanmış geleneksel değerlendirme ölçütleri kesinliği ve geri çağırmayı içerir. Tüm ölçümler, alaka düzeyine ilişkin bir zemin gerçeği kavramını varsayar: her belgenin belirli bir sorguyla ilgili olduğu veya olmadığı bilinir. Uygulamada, sorgular hatalı olabilir ve alaka düzeyinin farklı tonları olabilir.
Zaman çizelgesi
1900’lerden önce
1801: Joseph Marie Jacquard, bir dizi işlemi kontrol etmek için delikli kartları kullanan ilk makine olan Jakarlı tezgahı icat etti.
1880’ler: Herman Hollerith, makine tarafından okunabilen bir ortam olarak delikli kartları kullanan bir elektro-mekanik veri tablosu icat etti.
1890 Hollerith kartları, 1890 US Census verilerini işlemek için kullanılan anahtar zımbalar ve cetveller.
1920’ler-1930’lar
Emanuel Goldberg, mikrofilme alınmış belge rulolarındaki meta verileri aramak için fotoelektrik hücreler ve örüntü tanıma kullanan bir belge arama motoru olan “İstatistiksel Makine” için patentler sunar.
1940’lar–1950’ler
1940’ların sonu: ABD ordusu, Almanlardan ele geçirilen savaş zamanı bilimsel araştırma belgelerini indeksleme ve geri alma sorunlarıyla karşı karşıya kaldı.
1945: Vannevar Bush’un As We May Think adlı kitabı Atlantic Monthly’de çıktı.
1947: Hans Peter Luhn (1941’den beri IBM’de araştırma mühendisi), kimyasal bileşikleri aramak için mekanize delikli kart tabanlı bir sistem üzerinde çalışmaya başladı.
1950’ler: ABD’de SSCB ile bir “bilimsel boşluk” için artan endişe motive edildi, finansman teşvik edildi ve mekanize literatür tarama sistemleri (Allen Kent ve diğerleri) ve Eugene Garfield tarafından atıf indeksinin icadı için bir zemin sağladı.
1950: “Bilgi alma” terimi Calvin Mooers tarafından icat edildi.[10]
1951: Philip Bagley, MIT’de bir yüksek lisans tezinde bilgisayarlı belge erişiminde ilk deneyi gerçekleştirdi.[11]
1955: Allen Kent, Case Western Reserve Üniversitesi’ne katıldı ve sonunda Dokümantasyon ve İletişim Araştırmaları Merkezi’nin müdür yardımcısı oldu. Aynı yıl, Kent ve meslektaşları American Documentation’da kesinlik ve geri çağırma önlemlerini açıklayan ve ayrıca geri getirilemeyen ilgili belgelerin sayısını belirlemek için istatistiksel örnekleme yöntemlerini içeren bir IR sistemini değerlendirmek için önerilen bir “çerçeveyi” detaylandıran bir makale yayınladılar.[12] ]
1958: Uluslararası Bilimsel Bilgi Konferansı Washington DC, belirlenen sorunlara bir çözüm olarak IR sistemlerinin değerlendirilmesini dahil etti. Bakınız: Uluslararası Bilimsel Bilgi Konferansı Bildirileri, 1958 (Ulusal Bilimler Akademisi, Washington, DC, 1959)
1959: Hans Peter Luhn “Bilgi alımı için belgelerin otomatik kodlanması”nı yayınladı.
1960’lar:
1960’ların başı: Gerard Salton Harvard’da Uluslararası İlişkiler üzerine çalışmaya başladı, daha sonra Cornell’e taşındı.
1960: Melvin Earl Maron ve John Lary Kuhns[13] Journal of the ACM 7(3):216–244, Temmuz 1960’ta “İlgililik, olasılık indeksleme ve bilgi alma üzerine” yayınladılar.
1962:
Cyril W. Cleverdon, IR sistem değerlendirmesi için bir model geliştirerek Cranfield çalışmalarının ilk bulgularını yayınladı. Bakınız: Cyril W. Cleverdon, “İndeksleme Sistemlerinin Karşılaştırmalı Verimliliğine İlişkin Bir Araştırmanın Test Edilmesi ve Analizi Üzerine Rapor”. Cranfield Havacılık Koleksiyonu, Cranfield, İngiltere, 1962.
Kent, Bilgi Analizi ve Erişimini yayınladı.
1963:
Weinberg’in “Bilim, Hükümet ve Bilgi” raporu, “bilimsel bilgi krizi” fikrinin tam bir ifadesini verdi. Rapor, Dr. Alvin Weinberg’in adını almıştır.
Joseph Becker ve Robert M. Hayes, bilgi erişimi üzerine bir metin yayınladılar. Becker, Yusuf; Hayes, Robert Mayo. Bilgi depolama ve alma: araçlar, öğeler, teoriler. New York, Wiley (1963).
1964:
Karen Spärck Jones, Cambridge, Synonymy and Semantic Classification’daki tezini bitirdi ve Uluslararası İlişkiler için geçerli olan hesaplamalı dilbilim üzerinde çalışmaya devam etti.
Ulusal Standartlar Bürosu, “Mekanize Dokümantasyon için İstatistiksel Birleştirme Yöntemleri” başlıklı bir sempozyuma sponsor oldu. G. Salton’ın SMART sistemine ilk yayınlanan referansı (inanıyoruz) dahil olmak üzere çok sayıda önemli makale.
1960’ların ortası:
Ulusal Tıp Kütüphanesi, makine tarafından okunabilen ilk büyük veri tabanı ve yığın alma sistemi olan MEDLARS Tıbbi Literatür Analizi ve Erişim Sistemini geliştirdi.
MIT’de Proje Intrex.
1965: J. C. R. Licklider, Geleceğin Kitaplıkları’nı yayımladı.
1966: Don Swanson, Chicago Üniversitesi’nde Gelecekteki Kataloglar İçin Gereksinimler konulu çalışmalara dahil oldu.
1960’ların sonu: F. Wilfrid Lancaster, MEDLARS sisteminin değerlendirme çalışmalarını tamamladı ve bilgi erişimi konusundaki metninin ilk baskısını yayınladı.
1968:
Gerard Salton Otomatik Bilgi Organizasyonu ve Geri Alma’yı yayınladı.
John W. Sammon, Jr.’ın RADC Tech raporu “Bilgi Depolama ve Erişimin Bazı Matematiği…” vektör modelinin ana hatlarını çizdi.
1969: Sammon’un “Veri yapısı analizi için doğrusal olmayan bir eşleme 2017-08-08 tarihinde Wayback Machine’de arşivlendi” (IEEE Transactions on Computers), bir IR sistemine görselleştirme arabirimi için ilk teklifti.
1970’ler
1970’lerin başı:
İlk olarak hat sistemleri—NLM’nin AIM-TWX, MEDLINE; Lockheed’in Diyaloğu; SDC’nin ORBIT’i.
Theodor Nelson hipermetin kavramını tanıtıyor, Computer Lib/Dream Machines’i yayınladı.
1971: Nicholas Jardine ve Cornelis J. van Rijsbergen, “kümelenme hipotezini” ifade eden “Bilgi erişiminde hiyerarşik kümelemenin kullanımı”nı yayınladılar.[14]
1975: Salton’un son derece etkili üç yayını, vektör işleme çerçevesini ve terim ayrım modelini tam olarak ifade etti:
Bir İndeksleme Teorisi (Endüstriyel ve Uygulamalı Matematik Derneği)
Otomatik Metin Analizinde Bir Terim Önemi Teorisi (JASIS v. 26)
Otomatik İndeksleme için Vektör Uzayı Modeli (CACM 18:11)
1978: İlk ACM SIGIR konferansı.
1979: CJ van Rijsbergen Bilgi Erişimini (Butterworths) yayınladı. Olasılıksal modellere yoğun vurgu.
1979: Tamas Doszkocs, Ulusal Tıp Kütüphanesinde MEDLINE için CITE doğal dil kullanıcı arayüzünü uyguladı. CITE sistemi, serbest biçimli sorgu girişini, sıralanmış çıktıyı ve alaka düzeyi geri bildirimini destekledi.[15]
1980’ler
1980: İlk uluslararası ACM SIGIR konferansı, Cambridge’deki British Computer Society IR grubuyla ortaklaşa.
1982: Nicholas J. Belkin, Robert N. Oddy ve Helen M. Brooks bilgi alımı için ASK (Anormal Bilgi Durumu) bakış açısını önerdiler. Bu önemli bir kavramdı, ancak otomatik analiz araçları nihayetinde hayal kırıklığı yarattı.
1983: Salton (ve Michael J. McGill), vektör modellerine büyük önem vererek Introduction to Modern Information Retrieval’ı (McGraw-Hill) yayınladı.
1985: David Blair ve Bill Maron şunu yayınladı: Tam Metin Belge Alma Sistemi İçin Alma Etkinliğinin Değerlendirilmesi
1980’lerin ortası: Ticari IR sistemlerinin son kullanıcı versiyonlarını geliştirme çabaları.
1985–1993: Görselleştirme arayüzleri için önemli makaleler ve deneysel sistemler.
Donald B. Crouch, Robert R. Korfhage, Matthew Chalmers, Anselm Spoerri ve diğerlerinin çalışmaları.
1989: CERN’de Tim Berners-Lee tarafından ilk World Wide Web önerileri.
1990’lar
1992: İlk TREC konferansı.
1997: Görselleştirme ve çoklu referans noktası sistemlerine vurgu yapan Korfhage’s Information Storage and Retrieval[16] kitabının yayınlanması.
1999: Tüm IR’yi kapsamaya çalışan ilk kitap olan Ricardo Baeza-Yates ve Berthier Ribeiro-Neto’nun Addison Wesley tarafından yazılan Modern Information Retrieval adlı kitabı yayınlandı.
1990’ların sonu: Daha önce yalnızca deneysel IR sistemlerinde bulunan birçok özelliğin web arama motorları tarafından uygulanması. Arama motorları, IR modellerinin en yaygın ve belki de en iyi örneği haline gelir.
Kaynaklar:
https://en.wikipedia.org/wiki/Information_retrieval
https://en.wikipedia.org/wiki/File:Information-Retrieval-Models.png
Wiki Kaynaklar:
1)Luk, R. W. P. (2022). “Why is information retrieval a scientific discipline?”. Foundations of Science. 27 (2): 427–453. doi:10.1007/s10699-020-09685-x. S2CID 220506422.
2)Jansen, B. J. and Rieh, S. (2010) The Seventeen Theoretical Constructs of Information Searching and Information Retrieval Archived 2016-03-04 at the Wayback Machine. Journal of the American Society for Information Sciences and Technology. 61(8), 1517-1534.
3)Goodrum, Abby A. (2000). “Image Information Retrieval: An Overview of Current Research”. Informing Science. 3 (2).
4)Foote, Jonathan (1999). “An overview of audio information retrieval”. Multimedia Systems. 7: 2–10. CiteSeerX 10.1.1.39.6339. doi:10.1007/s005300050106. S2CID 2000641.
5)Beel, Jöran; Gipp, Bela; Stiller, Jan-Olaf (2009). Information Retrieval On Mind Maps – What Could It Be Good For?. Proceedings of the 5th International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom’09). Washington, DC: IEEE. Archived from the original on 2011-05-13. Retrieved 2012-03-13.
6)Frakes, William B.; Baeza-Yates, Ricardo (1992). Information Retrieval Data Structures & Algorithms. Prentice-Hall, Inc. ISBN 978-0-13-463837-9. Archived from the original on 2013-09-28.
7)Singhal, Amit (2001). “Modern Information Retrieval: A Brief Overview” (PDF). Bulletin of the IEEE Computer Society Technical Committee on Data Engineering. 24 (4): 35–43.
8)Mark Sanderson & W. Bruce Croft (2012). “The History of Information Retrieval Research”. Proceedings of the IEEE. 100: 1444–1451. doi:10.1109/jproc.2012.2189916.
9)JE Holmstrom (1948). “‘Section III. Opening Plenary Session”. The Royal Society Scientific Information Conference, 21 June-2 July 1948: Report and Papers Submitted: 85.
10)Mooers, Calvin N.; The Theory of Digital Handling of Non-numerical Information and its Implications to Machine Economics (Zator Technical Bulletin No. 48), cited in Fairthorne, R. A. (1958). “Automatic Retrieval of Recorded Information”. The Computer Journal. 1 (1): 37. doi:10.1093/comjnl/1.1.36.
11)Doyle, Lauren; Becker, Joseph (1975). Information Retrieval and Processing. Melville. pp. 410 pp. ISBN 978-0-471-22151-7.
12)Perry, James W.; Kent, Allen; Berry, Madeline M. (1955). “Machine literature searching X. Machine language; factors underlying its design and development”. American Documentation. 6 (4): 242–254. doi:10.1002/asi.5090060411.
13)Maron, Melvin E. (2008). “An Historical Note on the Origins of Probabilistic Indexing” (PDF). Information Processing and Management. 44 (2): 971–972. doi:10.1016/j.ipm.2007.02.012.
14)N. Jardine, C.J. van Rijsbergen (December 1971). “The use of hierarchic clustering in information retrieval”. Information Storage and Retrieval. 7 (5): 217–240. doi:10.1016/0020-0271(71)90051-9.
15)Doszkocs, T.E. & Rapp, B.A. (1979). “Searching MEDLINE in English: a Prototype User Interface with Natural Language Query, Ranked Output, and relevance feedback,” In: Proceedings of the ASIS Annual Meeting, 16: 131-139.
16)Korfhage, Robert R. (1997). Information Storage and Retrieval. Wiley. pp. 368 pp. ISBN 978-0-471-14338-3.


